# filter to kale
kale <- alldata %>%
filter(crop == "kale")
# attempt to drop missing data
kale_varieties <- kale %>%
drop_na(variety) # this doesn't work b/c the empty cells aren't actually read as NA
# alternative way to drop missing data
kale_varieties <- kale %>%
filter(variety != "")
# this works to remove rows with empty variety values
# this says, keep all rows where variety does NOT equal "" (empty)
# the ! in R means 'not'
Clean duplicate variety names
# generate a table of all kale variety names
table(kale_varieties$variety)
# use case_match() to replace duplicate names
# first argument is variable name (variety)
# next is a list of "original value" ~ "replacement value"
# .default = variety says that if a match is not present in the list,
# default to the original value (for those values that don't need replacing)
kale_var_clean <- kale_varieties %>%
mutate(var_clean = case_match(
variety,
"red_russian,red russian" ~ "red_russian",
"white_russian,red russian" ~ "mixed",
"dazzling_blue_laacinato" ~ "lacinato",
.default = variety),
var_title = str_to_title(var_clean) # capitalize first letter of each name
)
# check that it worked
table(kale_var_clean$var_title)
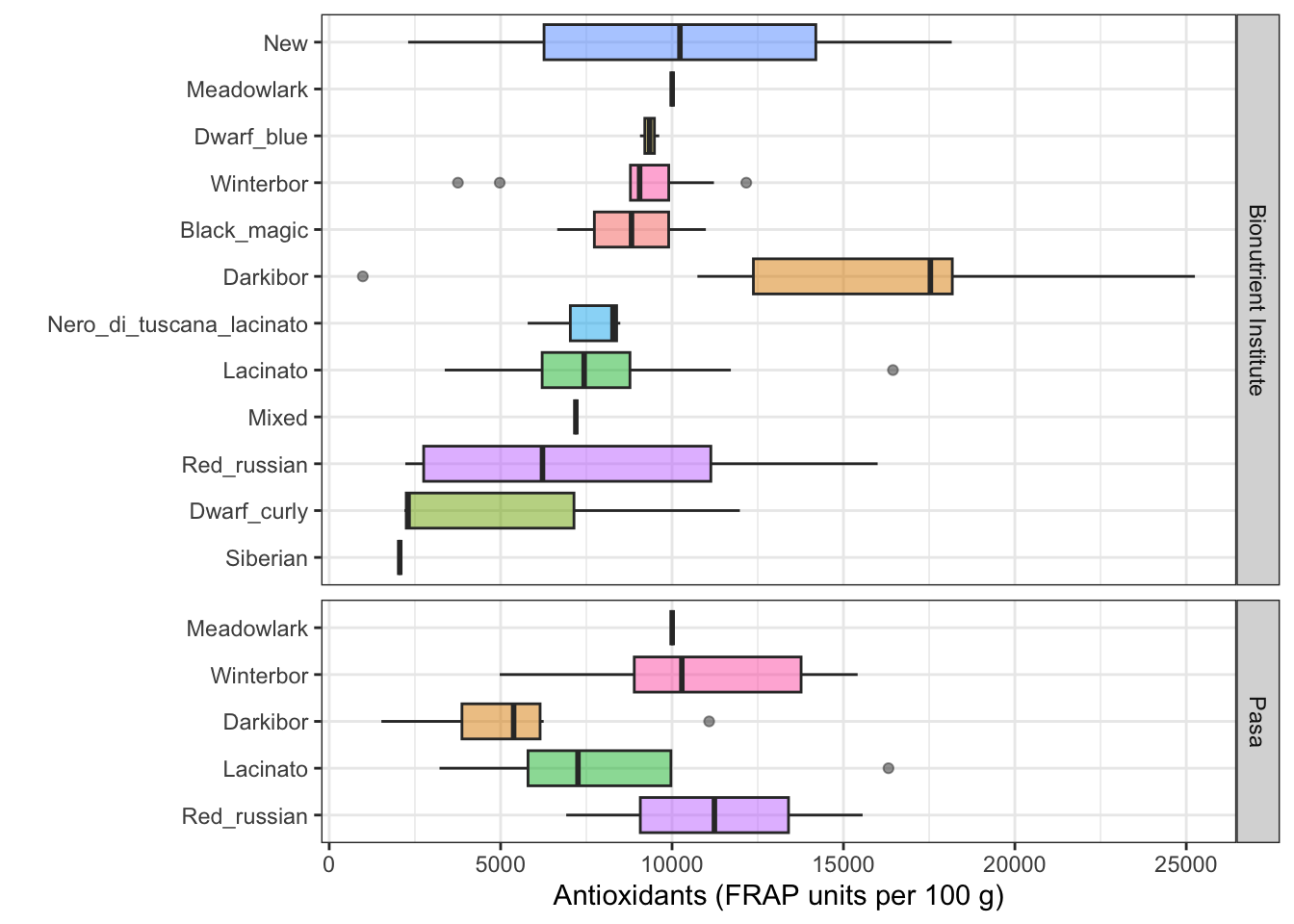
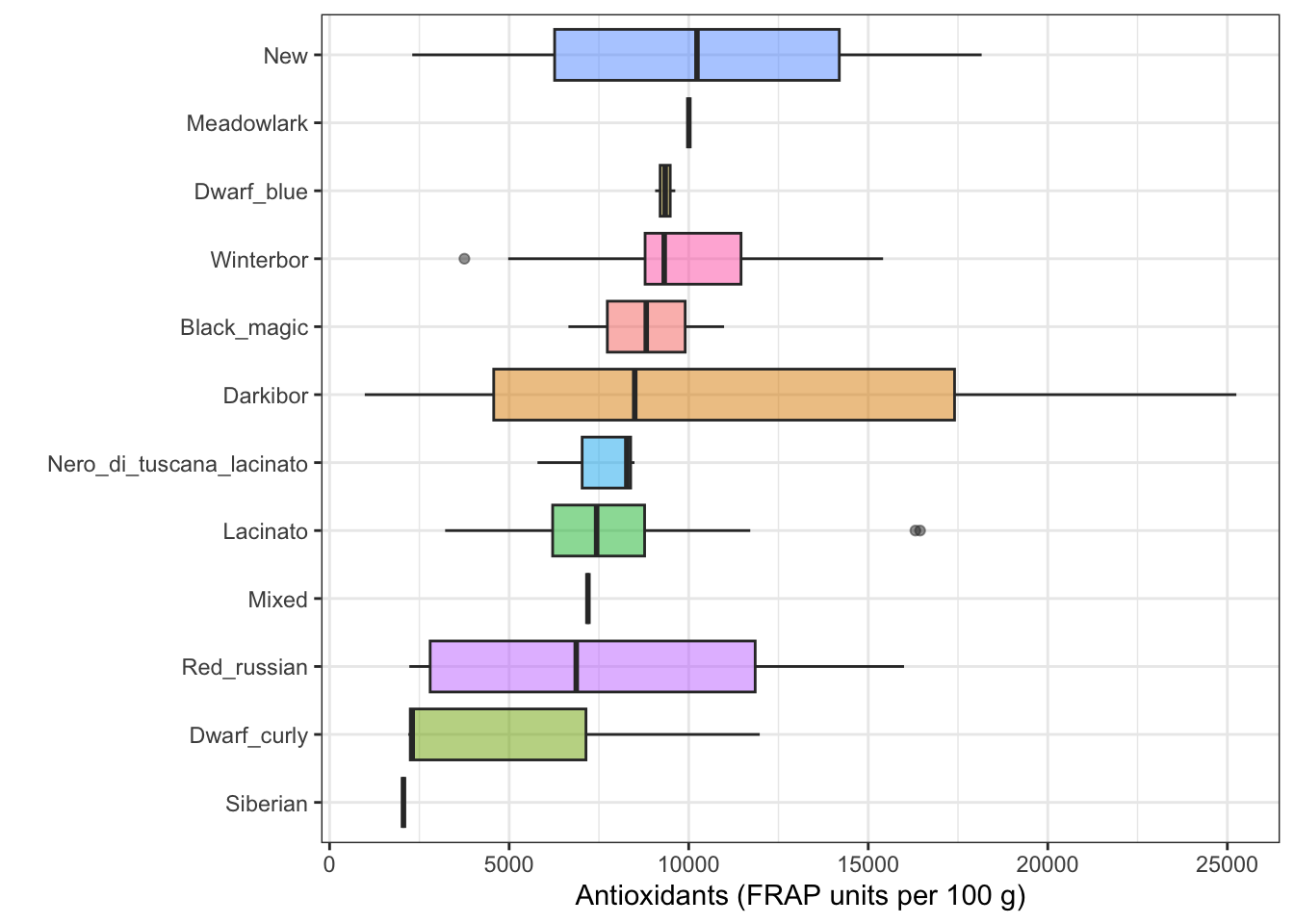
This shows that the sorting works without the facets - supporting
the idea that the strange result in the faceted version is driven by
calculating the median (or mean) across groups
ggplot(kale_var_clean,
aes(x = fct_reorder(var_title, antioxidants, .fun = median), # .fun = median to sort by median (not mean)
y = antioxidants, fill = var_title)) +
geom_boxplot(alpha= 0.5) +
# facet_grid(group ~., scales="free", space = "free") +
theme_bw() +
xlab("") +
ylab("Antioxidants (FRAP units per 100 g)") +
theme(legend.position = "none")+
coord_flip()